Tutorial v1.0.0¶
The aim of this tutorial is to give a basic introduction to the main workflow of
scousepy. Each stage will be described below along with some of the
important customisable keywords. All data for the tutorial can be found here, along with some example
scripts.
Data¶
This tutorial utilises observations of N2H+ (1-0) towards the Infrared Dark Cloud G035.39-00.33. This data set was first published in Henshaw et al. 2013.. These observations were carried out with the IRAM 30m Telescope. IRAM is supported by INSU/CNRS (France), MPG (Germany) and IGN (Spain). The data file is in fits format and is called
n2h+10_37.fits
Getting Started¶
scousepy requires several key parameters that are worth setting as global
parameters. These can be set in the following way
filename = 'n2h+10_37'
datadirectory = './'
wsaa = [8.0]
outputdir = './myoutputdirectory/' # optional
ppv_vol = [32.0,42.0,None,None,None,None] # optional
mask_below = 0.3 # optional
Here filename is provided without the .fits extension. datadirectory
points to the location of the data. By default scousepy will create a new
directory in the same location as the input file. However, this can be changed
with the optional keyword outputdir. wsaa is used during stage 1. It
defines the maximum width of the region used to generate spatially averaged
spectra (see below).
The optional keywords listed above include ppv_vol, which allows the user to
control the region of the datacube over which to perform the fitting, and
mask_below which is used to mask the integrated intensity map produced
during stage 1. ppv_vol is provided as a list and given in the format
ppv_vol = [min_vel, max_vel, min_y, max_y, min_x, max_x].
These are the ranges over which the fitting will be performed. This tutorial
is tuned to the n2h+ data, which has hyperfine structure. Here we implement the
range 32-42 km/s since this allows us to focus on the isolated hyperfine
component, which we model as a Gaussian.
Stage 1: defining the coverage¶
As discussed in the description of the code, the purpose of stage 1 is to identify the spatial area over which to fit the data. Stage 1 requires several key parameters. To run stage 1 you can use
s = scouse.stage_1(filename, datadirectory, wsaa,
ppv_vol=ppv_vol,
outputdir=outputdir,
mask_below=mask_below,
fittype='gaussian',
verbose = True,
write_moments=True,
save_fig=True)
Here I’ve used the keywords write_moments=True and save_fig=True. The
former will produce FITS files of the zeroth, first, and second order moments of
the data. It will also create a FITS file containing the spectral coordinate of
the maximum value of the spectrum. The latter keyword creates a simple plot of
the coverage that will be used during the fitting procedure. The terminal output
should look something like this…

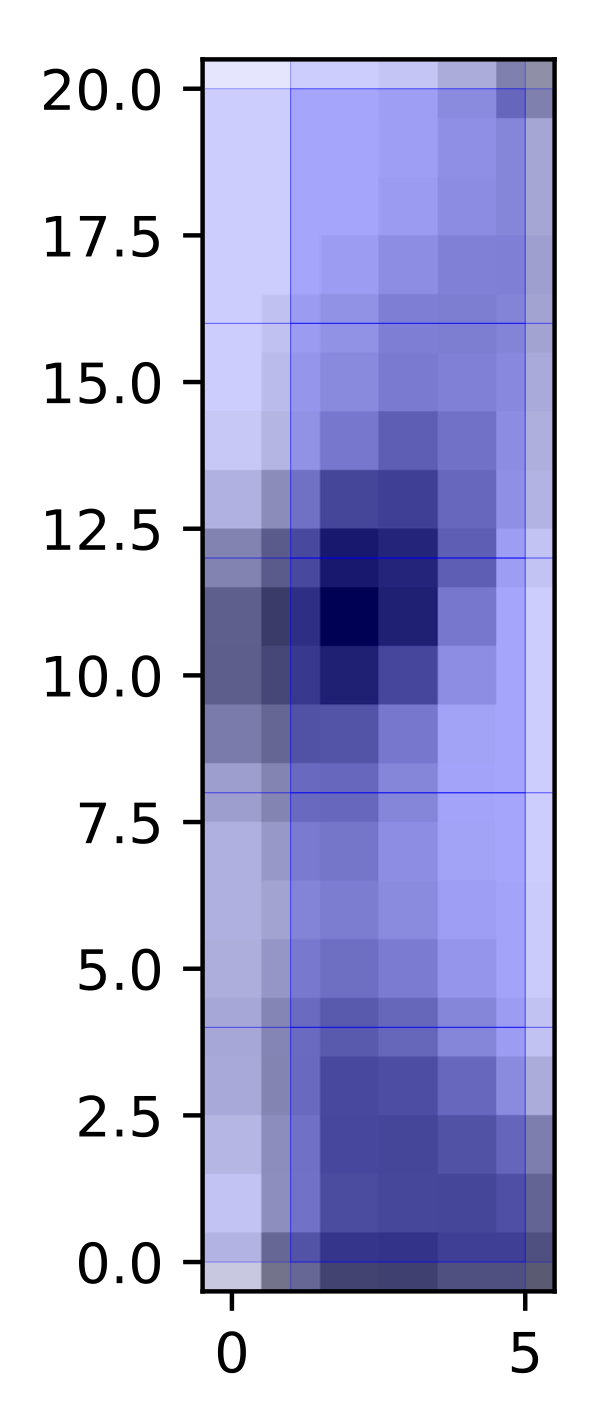
Where it tells us that we will have to fit a total of 12 spatially averaged spectra and that the total number of spectra to fit is 126. The output coverage map for this particular tutorial is not much to look at, but here it is anyway…
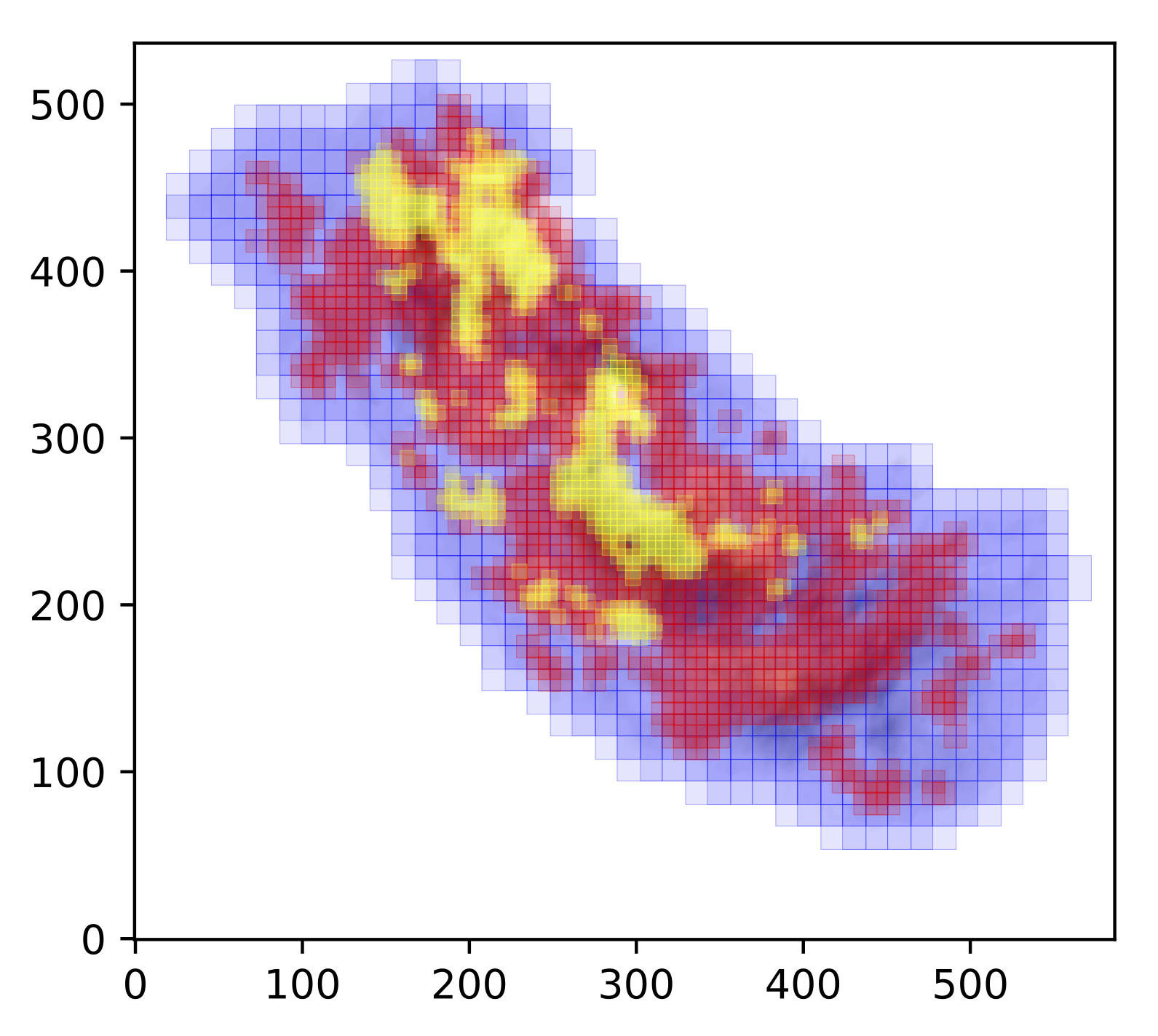
Below is a slightly more interesting example where the refine_grid keyword
has been set. This outputs spectral averaging areas of different sizes. The
basic idea is to reduce the size of the SAAs based on the spectral complexity
in a given location. In this case we define spectral complexity by making a
comparison between the moment 1 map (intensity-weighted average velocity) and
the velocity at peak emission map. In theory, if the spectrum is simple, e.g.
a single Gaussian, the difference between these two values should be close to 0.
On the other hand, if the spectrum is complex then the difference between these
two values is likely to be > 0. Below is the coverage defined for the central
molecular zone cloud G0.253+0.016, and presented in Henshaw et al. 2019. The
SAA sizes decrease from blue - red - yellow, with the yellow regions exhibiting
the most complex line-profiles.
Stage 2: fitting the spectral averaging areas¶
Stage 2 is where we will perform our manual fitting. It is simple to run using
s = scouse.stage_2(s, verbose=True, write_ascii=True)
where the keyword write_ascii has been set to output the best-fitting
solutions as an ascii file at the end of the fitting procedure. The fitting
process is based on the interactive process of pyspeckit. Initialising the fitter will look
a bit like this..
where we will have an indication of how many spectra we have to fit (and how
many we have already fitted), as well as some important info for the pyspeckit
interactive fitter. Upon running stage 2, a window should have popped up where
one of the spatially averaged spectra will be displayed. Interactive fitting
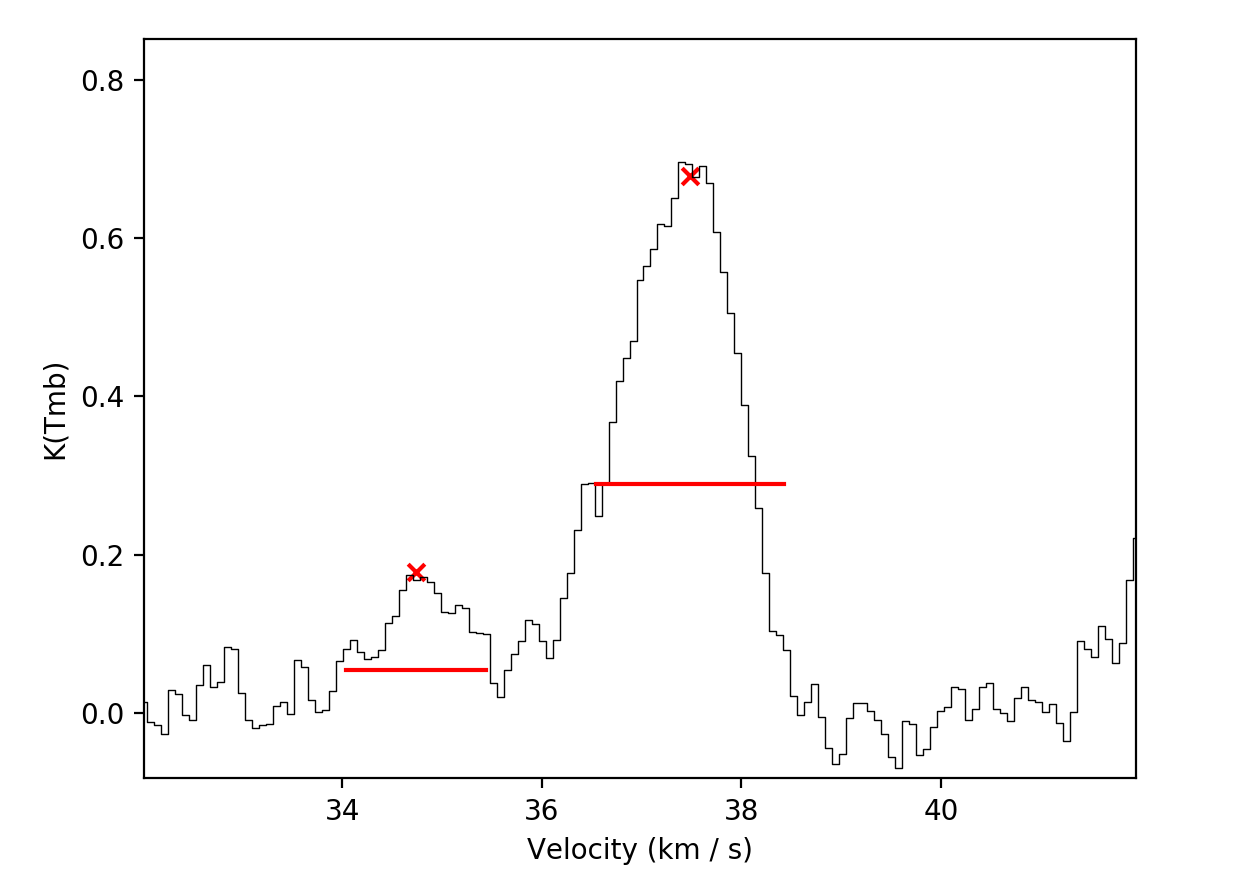
can be performed using several commands. To indicate components you would like
to fit select each component twice, once somewhere close to the peak emission
and another click to indicate (roughly) the full-width at half-maximum. In my
experience with this, you don’t need to be particularly accurate, pyspeckit
does an excellent job of picking up the components you have selected. Selection
can be made either using the keyboard (m) or mouse. Once selected this will
look something like this…
If you are happy with your fit, hitting d will lock it in. The resulting
fit will be plotted. At this point scousepy will output some useful information
to the terminal…

and will ask if you’re happy with the fit. If the fit looks good, press enter to continue. This will lock the fit in and overplot the individual components…
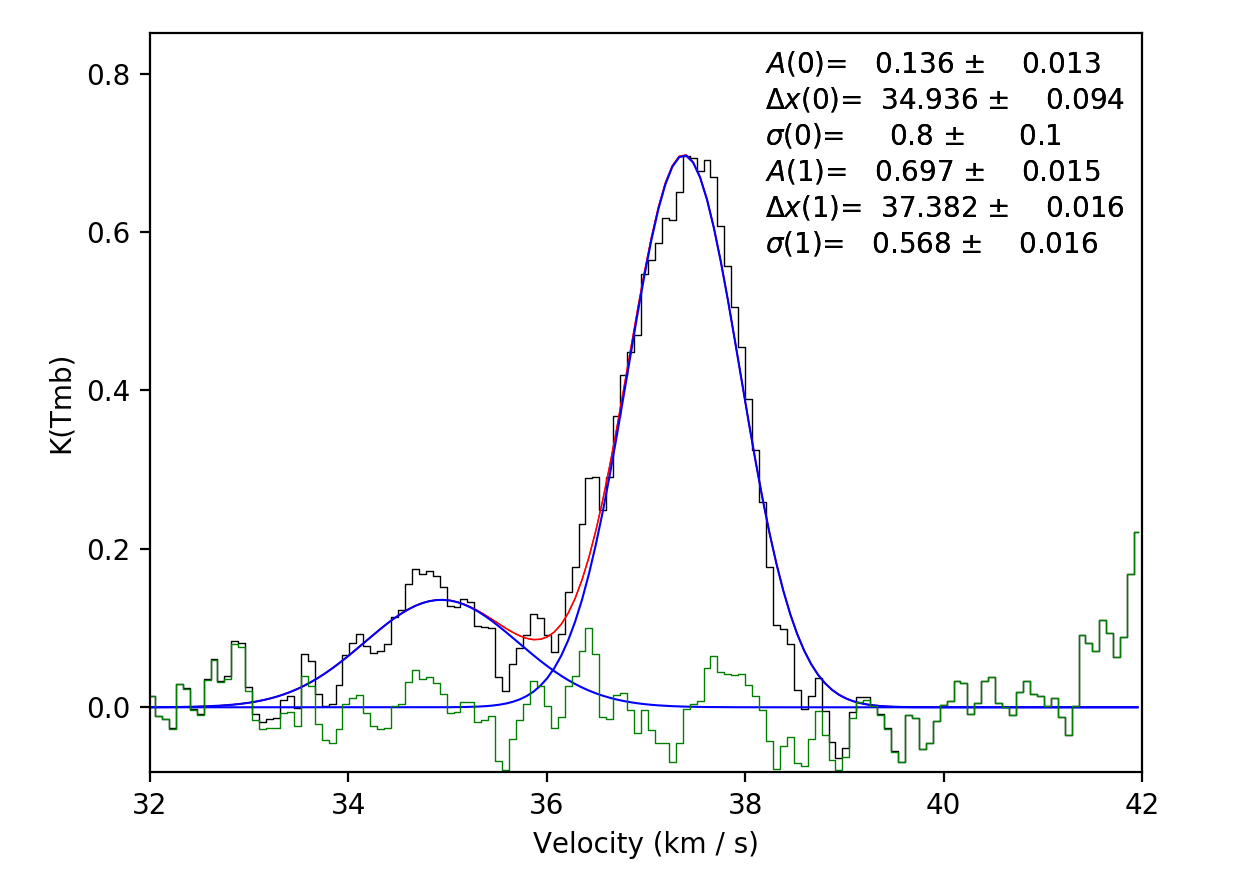
scousepy will then move onto the next spectrum. If you’re not happy with the
fit you can always re-enter the interactive fitter by typing f. Repeat this
process until the fitting is completed. Note that as a bit of a time-saver
scousepy will automatically try and fit the each spectrum with the previous
spectrum’s best-fitting solution. Often this leads to good fits and its possible
to simply press enter to cycle through a good chunk of the fits. However, this
can also obviously lead to some terrible fits, particularly if there is a big
jump in spatial location and therefore the spectrum changes considerably. If
this happens simply type f to re-enter the interactive fitter.
For large datasets its worth noting that there are a couple of keywords here
that might be useful, particularly bitesize. This enables the user to
perform bitesize fitting where the process is broken down into sessions and the
user fits a fixed number of spectra at any one time. The number of spectra to
fit in any one session can be controlled using the nspec keyword.
Stage 3: automated fitting¶
Stage 3 represents the automated decomposition stage. scousepy will take you
best-fitting solutions from stage 2 and pass these to the individual spectra
located within each SAA. The fitting process is controlled by a number of
tolerance levels which are passed to scousepy in the form of a list or an
array
njobs = 4
tol = [3.0, 2.0, 3.0, 3.0, 0.5]
s = scouse.stage_3(s, tol, njobs=njobs, verbose=True)
The tolerance levels are descibed more completely in Henshaw et al. 2016, however, in short, the first tolerance here is the S/N ratio each component must satisfy, the second is the minimum width of each component given as a multiple of the channel spacing, the third and fourth control how similar (in terms of velocity and width) a component must be to the closest matching component in the SAA fit, and the final tolerance governs the minimum separation between two components for them to be considered distinguishable (it is given as a multiple of the width of the narrowest component).
Something else to consider is the njobs keyword. The automated fitting procedure
is parallelised. Currently the parallelisation works by sending the fitting of
each SAA to a different node (rather than individual spectra). Perhaps there is
a better way to do this (suggestions welcome),
but it does lead to a bump in speed. I would say however, that in general
I’ve noticed a considerable reduction in speed in moving from IDL to Python.
This is particularly true in the case of complex data. For the G0.253+0.016 data
in Henshaw+ 2019, for example, 4, 5, 6 component fits are not uncommon. When
the number of components is high, each attempt may take ~ a second. If the fit
is unsatisfactory scousepy will try a new fit with a different number of
components. When combined with the fact that SAAs are overlapped such that many
of the spectra are fit more than once, it is easy to see how the time begins
to ramp up. As a rule of thumb I’d advise against running this stage on a laptop
in the case of complex data. For the G0.253+0.016 data, I set this running on
~ 20 cores and it crunched away over night. In contrast, running stage 3 on a
similarly sized dataset, but one which is dominated by 1-2 components on roughly
the same number of cores completed in ~ half an hour. So it really depends on
the dataset and the time taken for completion will vary. On a positive note you
can just set it going and leave it to do its thing.
Here is an example of the output to terminal for the tutorial data. In this
case the fitting was not parallelised (njobs=1)…

Stage 4: selecting the best-fitting solutions¶
Not much to say here - just set this stage running. Here the best-fitting solutions from stage 3 are compiled for each spectrum. Where the SAAs overlap there will be multiple fits for each spectrum. Duplicates are removed and the “best-fit” model solution is defined as that with the smallest AIC value.
s = scouse.stage_4(s, verbose=True)
Stage 5: quality control¶
Now we want to check our work. Stage 5 works interactively and is run in the following way
s = scouse.stage_5(s, blocksize = 6,
figsize = [18,10],
plot_residuals=True,
verbose=True)
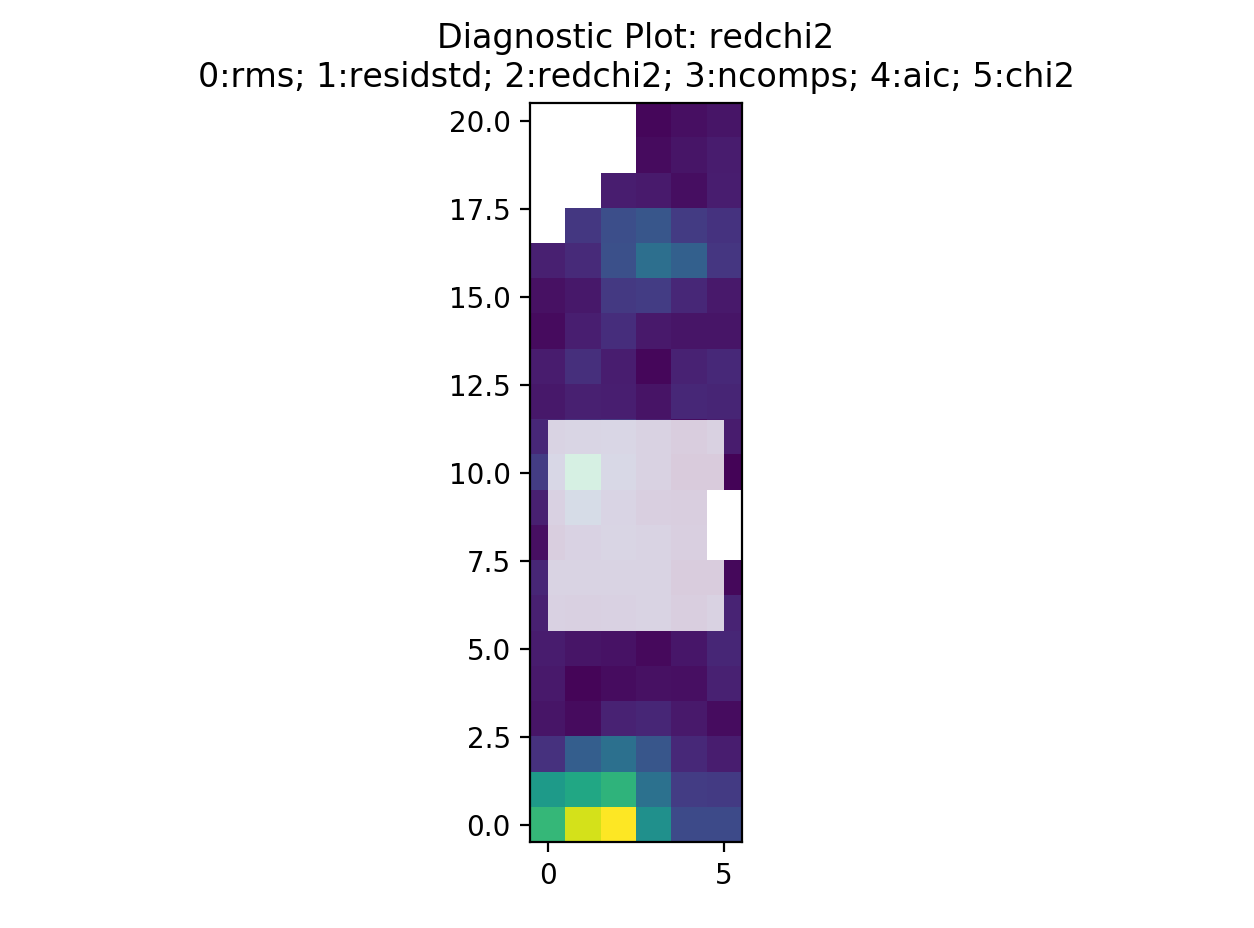
First, a bunch of diagnostic plots will be created (these are all saved to the stage 5 directory). These include plots of the rms, residuals, reduced chi-squared, number of components, aic, and the chi-squared. An interactive pop up window will be displayed which will look something like this…
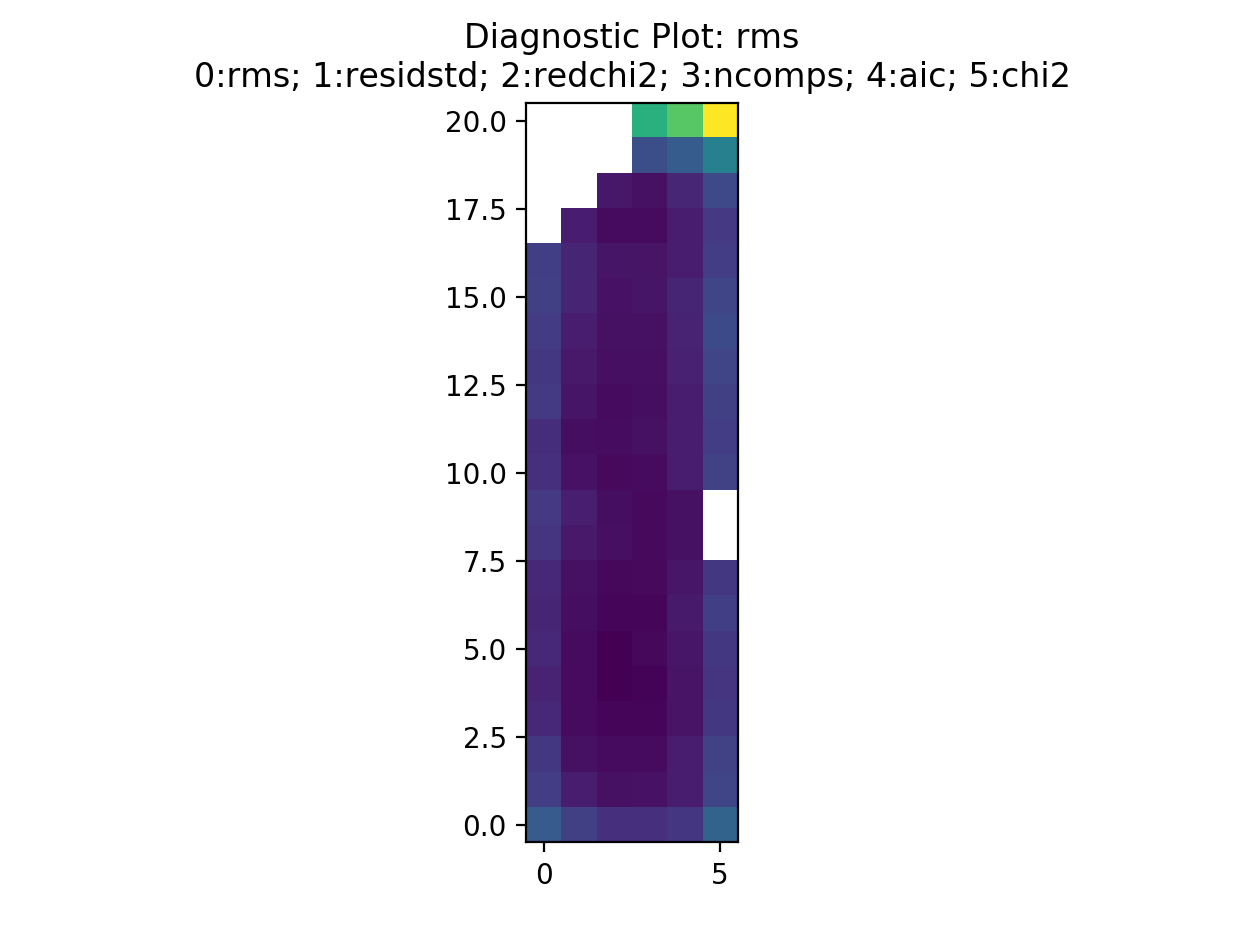
This is displaying the rms map. The displayed image can be changed by selecting a different number. For example, selecting 2 will display the reduced chi-squared…
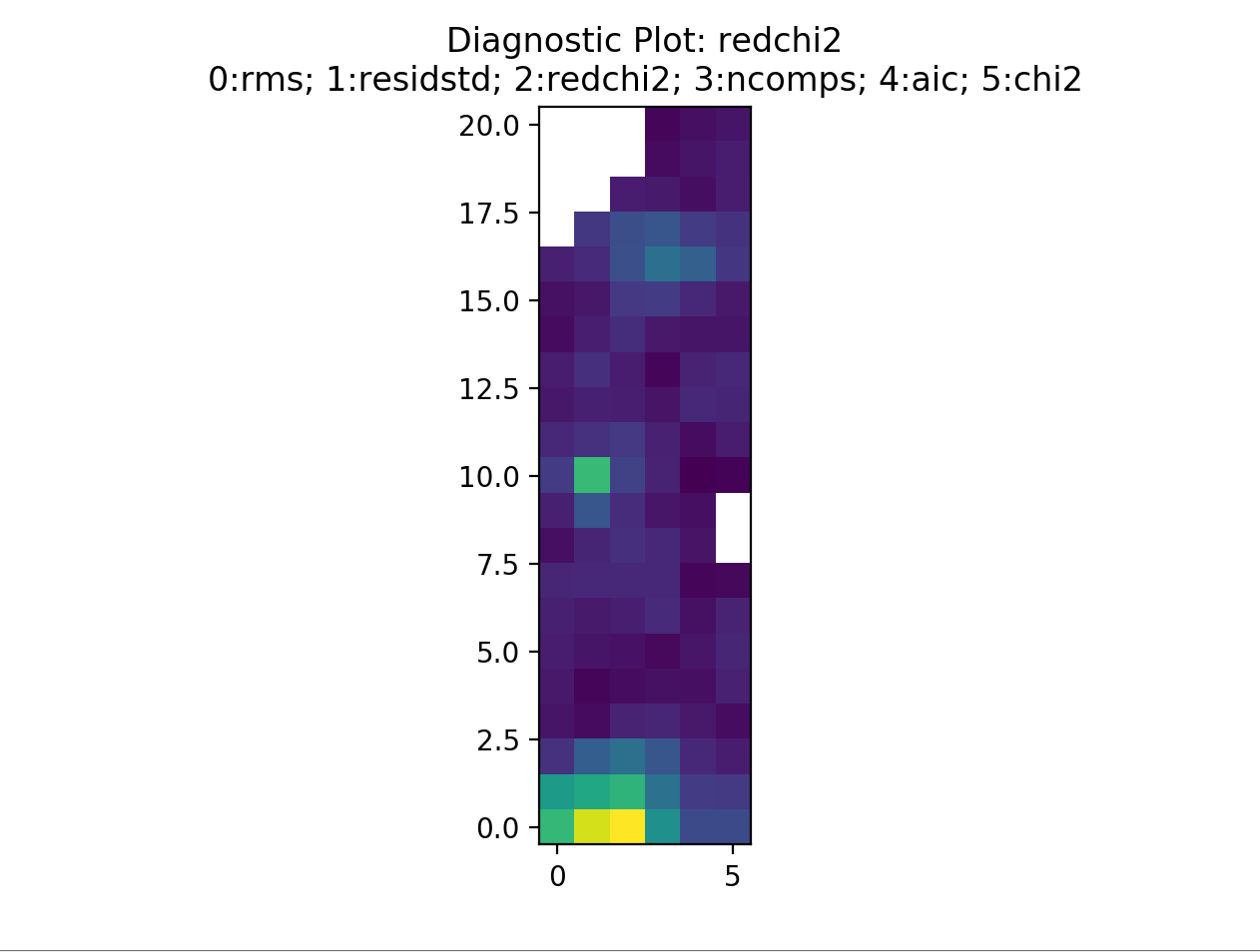
By selecting somewhere in the map a new pop up will be displayed. The number of
spectra that will be shown can be defined with the blocksize keyword. The
pop up window will look something like this…
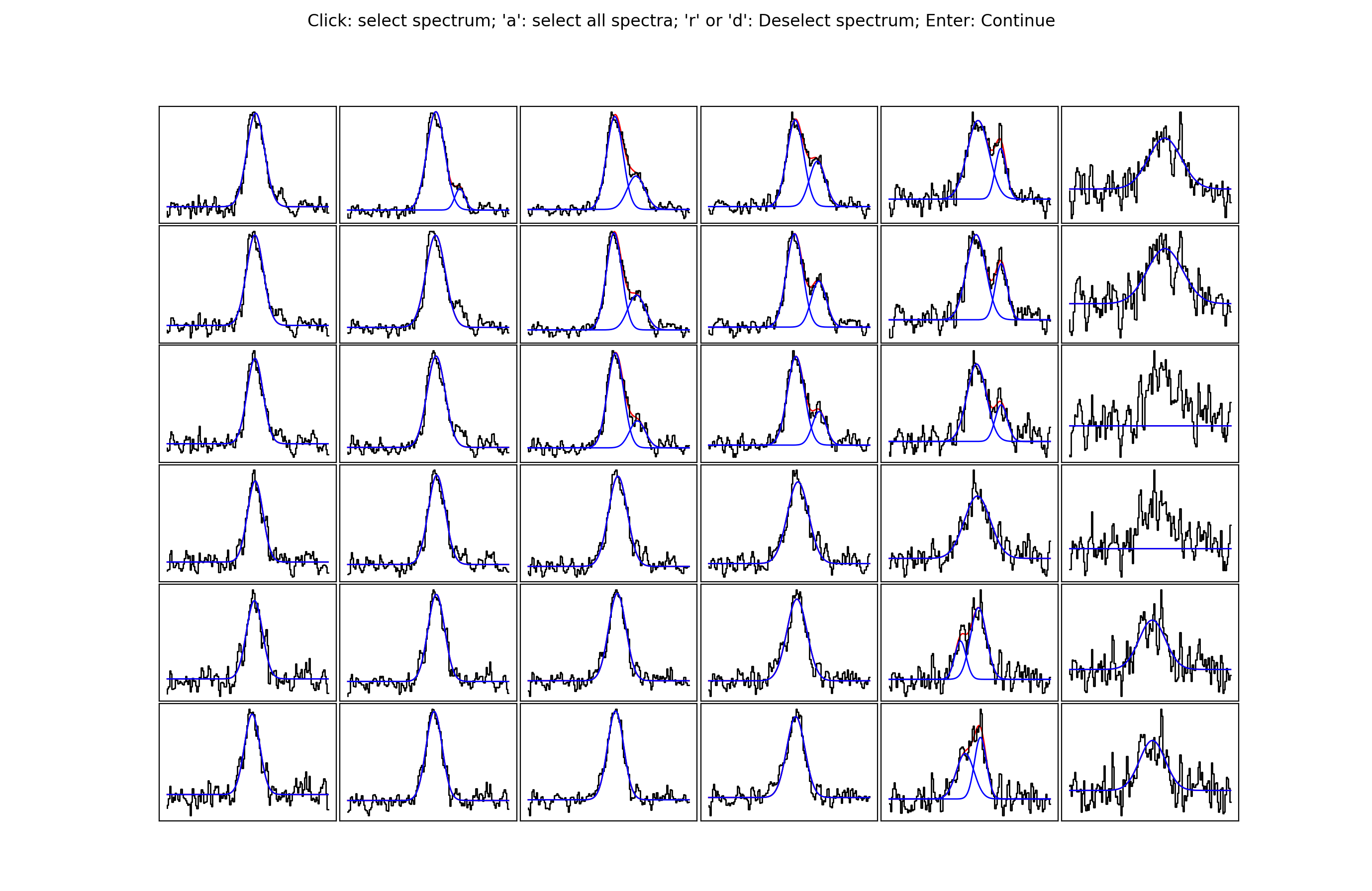
The idea behind this stage is to select spectra you may want to take a closer look at, either because you want to see if an alternative fit is available or because the fit is bad and you want to re-fit manually. Clicking on a spectrum will save it for inspection in stage 6. In the below image, I have selected some of the spectra close to the edge of the map. Clearly here the noise is greater and the fits aren’t as good…
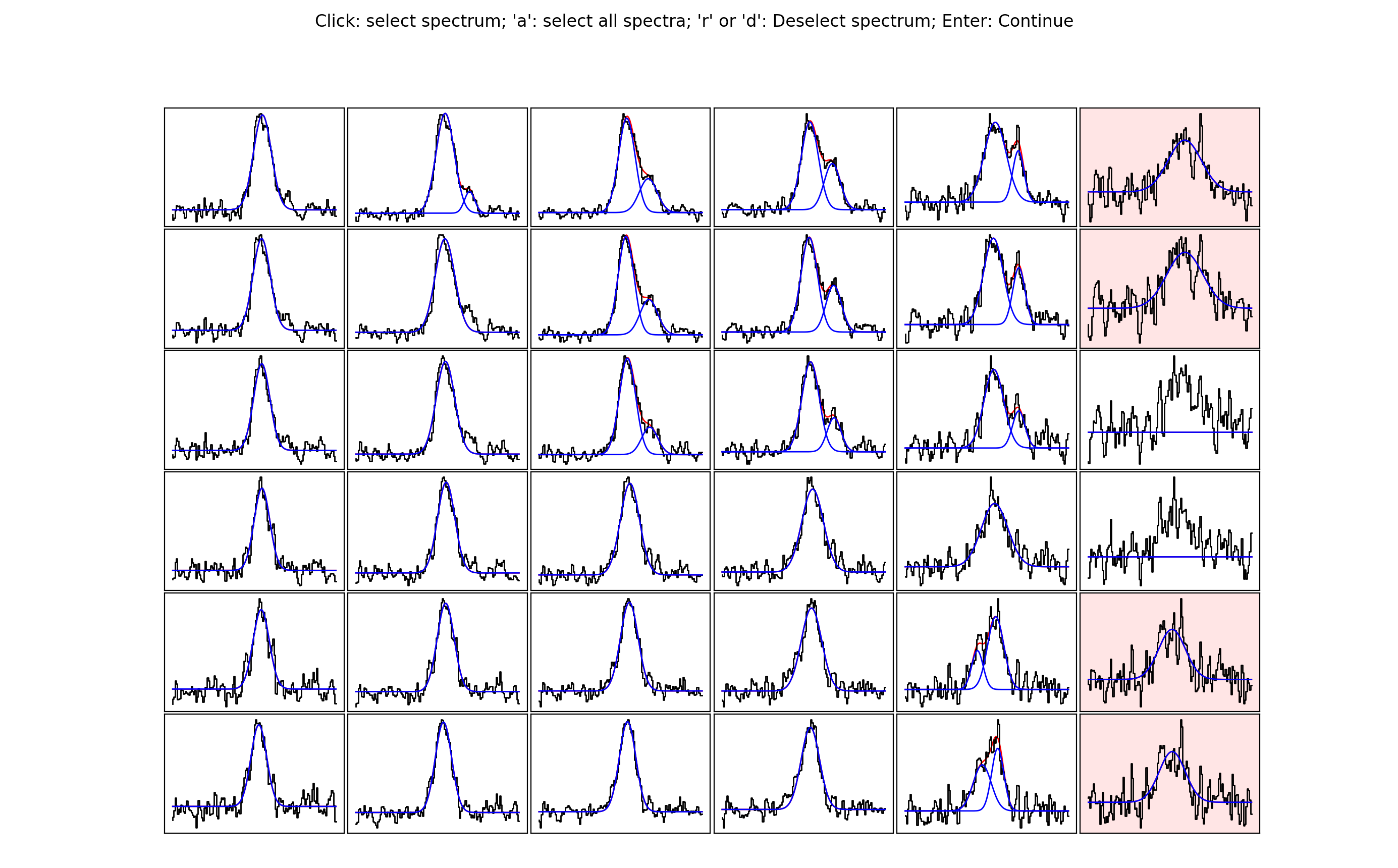
Note that if you are not happy with any of the spectra in a region you can
select all of them by pressing a. If you make a mistake, or would simply like
to remove a spectrum from the selection, hover over the spectrum with the cursor
and press r or d. Pressing enter on the pop up window with the spectra will
close it and allow you to select another region. A shaded region will show you
where you have already checked…
For a small dataset like that in the tutorial it is easy to check all spectra. However, you may want to stick to a representative sample for much bigger datasets.
For my own personal work flow I tend to have a very quick run through stage 5 without actually selecting any spectra. The idea is to have a quick glance at whether or not the fits are any good. If not, or if I feel I will have to do a lot of re-fitting (maybe >5-10% of the data), I will stop at this stage and tweak the parameters of stage 3 and re-run from there. Once I’m happy that the majority of the fits are reasonable I will go through stage 5 in earnest.
Stage 6: refitting¶
Here we are going to look again at the spectra we selected during stage 5. Stage 6 is run using
s = scouse.stage_6(s, plot_neighbours=True,
radius_pix = 2,
figsize = [18,10],
plot_residuals=True,
write_ascii=True,
verbose=True)
The plot_neighbours keyword here is optional. If set to True stage 6 will
begin by reminding you of each spectrum and its surroundings. This isn’t
particularly necessary for the tutorial data, but for large datasets, where it
easy to forget perhaps why a spectrum was selected for reevaluation, it can be
useful. If set to True, the first pop up window will look something like this…
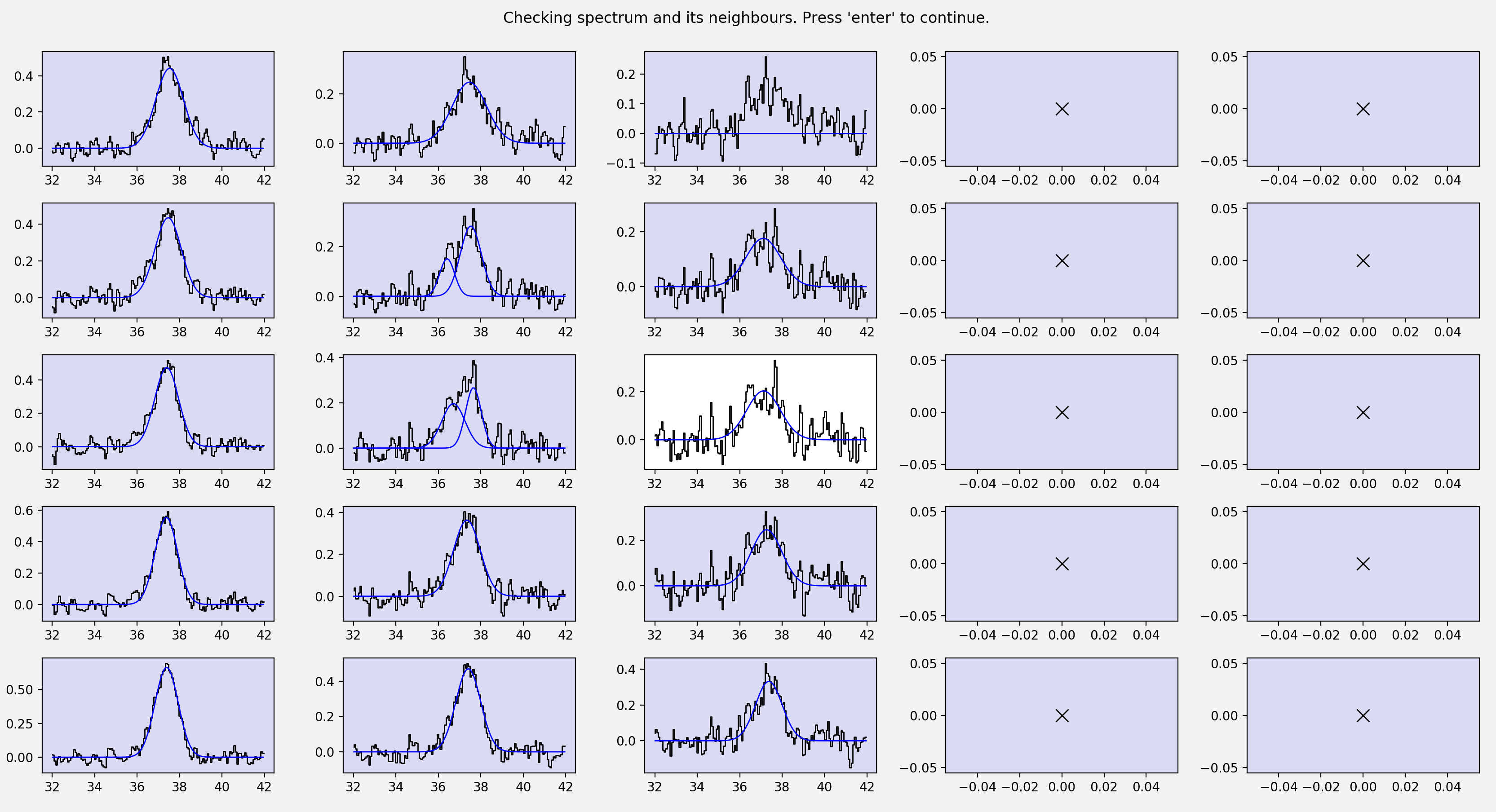
Here, the central pixel is the first pixel we selected during stage 5 (see above).
It is at the edge of the map (hence the pixels with X values). Pressing Enter
will move scousepy onto the next phase. At the next phase you will be
presented with a choice. scousepy will show the current fit and any other
alternative solutions to this spectrum. In the example below no alternatives are
available. However, scousepy will always provide a no-fit option. In my
personal experience I have found that sometimes having no-fit is better than
having a bad fit.
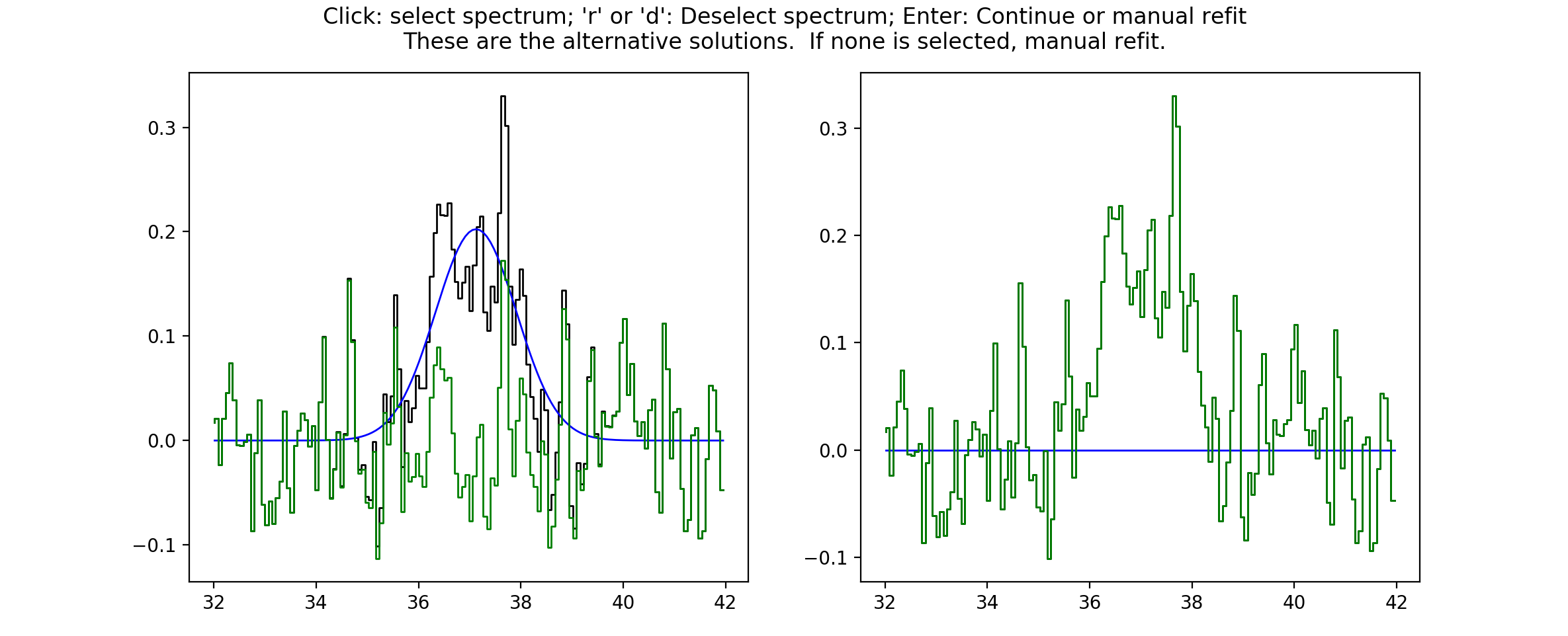
At this point you can make a choice. Either select the current spectrum, select an alternative, or press Enter to enter the interactive fitter you will now be familiar with from stage 2. Let’s say we aren’t happy with this fit but we also don’t think we can do a better job - we can click on the no-fit option like so…
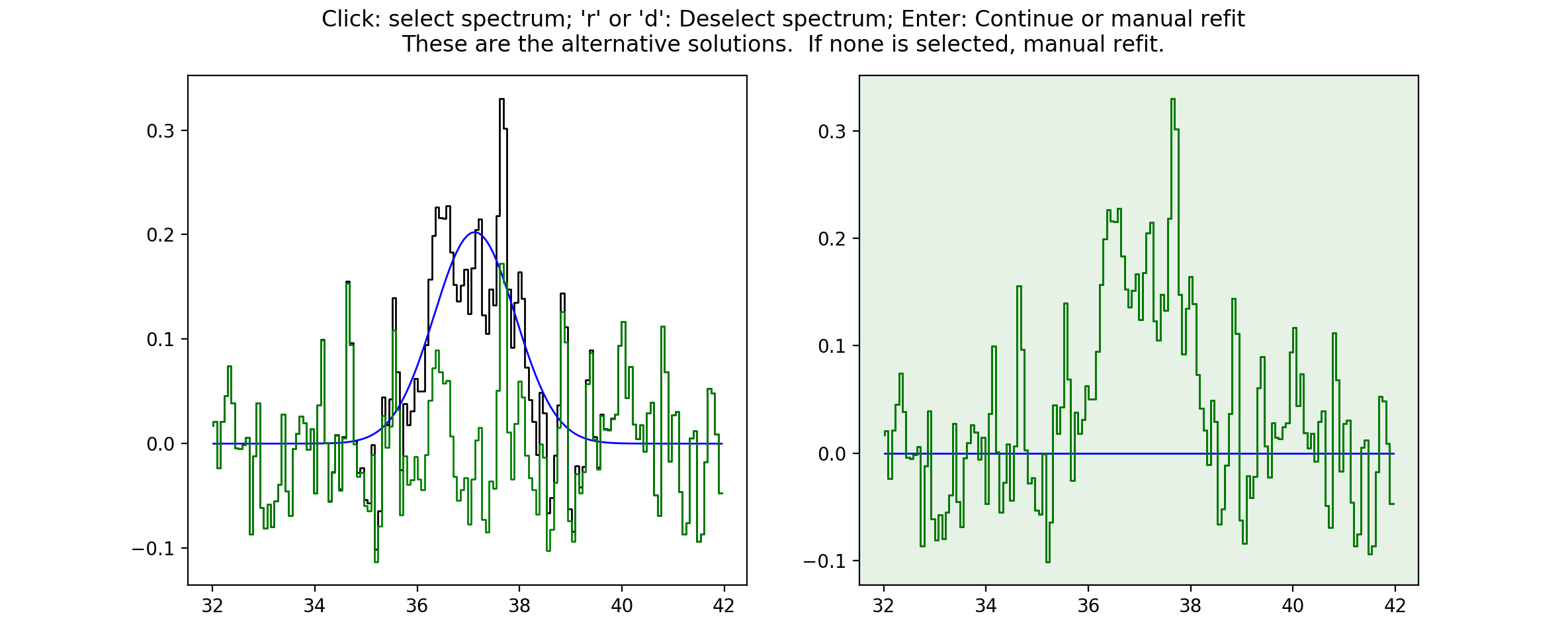
This will select the no-fit option and move on to the next spectrum. Moving on,
we see one we want to re-fit. Pressing Enter will enter the interactive fitter
from pyspeckit. Using the same commands as in stage 2 we can try to fit
two components like so…
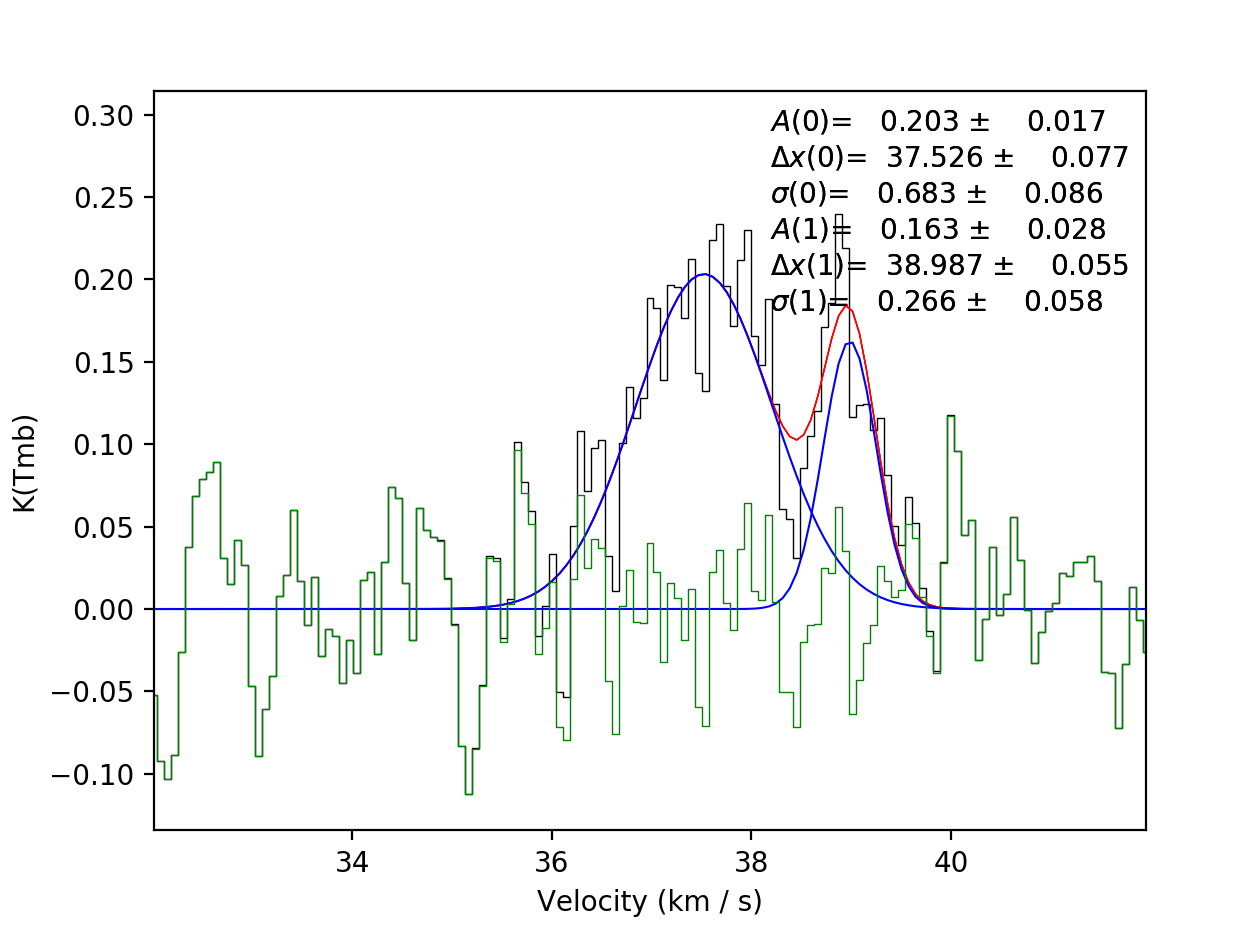
and as before, scousepy will give you a running commentary on what is
happening in the terminal…

Repeat this process until all of the spectra selected in stage 5 have been checked over. As with stage 2, stages 5 and 6 can be run in bitesize mode. This type of fitting is a little more fiddly and will be described below.
Complete Example¶
In reality you might not want to run all of the stages back to back. To save
memory each output file produced by scousepy only contains essential
information. An example code to run scousepy may therefore look something
like this…
from scousepy import scouse
from astropy.io import fits
import os
pl.ion()
def run_scousepy():
datadirectory = '../data/'
outputdir = '../output/simple_example_run/'
filename = 'n2h+10_37'
ppv_vol = [32.0,42.0,None,None,None,None]
wsaa = [8.0]
tol = [3.0, 1.0, 3.0, 3.0, 0.5]
verb = True
fittype = 'gaussian'
njobs = 4
mask = 0.3
#==========================================================================#
# Stage 1
#==========================================================================#
if os.path.exists(outputdir+filename+'/stage_1/s1.scousepy'):
s = scouse(outputdir=outputdir, filename=filename, fittype=fittype,
datadirectory=datadirectory)
s.load_stage_1(outputdir+filename+'/stage_1/s1.scousepy')
s.load_cube(fitsfile=datadirectory+filename+".fits")
else:
s = scouse.stage_1(filename, datadirectory, wsaa,
ppv_vol=ppv_vol,
outputdir=outputdir,
mask_below=mask,
fittype=fittype,
verbose = verb,
write_moments=True,
save_fig=True)
#==========================================================================#
# Stage 2
#==========================================================================#
if os.path.exists(outputdir+filename+'/stage_2/s2.scousepy'):
s.load_stage_2(outputdir+filename+'/stage_2/s2.scousepy')
else:
s = scouse.stage_2(s, verbose=verb, write_ascii=True)
#==========================================================================#
# Stage 3
#==========================================================================#
if os.path.exists(outputdir+filename+'/stage_3/s3.scousepy'):
s.load_stage_3(outputdir+filename+'/stage_3/s3.scousepy')
else:
s = scouse.stage_3(s, tol, njobs=njobs, verbose=verb)
#==========================================================================#
# Stage 4
#==========================================================================#
if os.path.exists(outputdir+filename+'/stage_4/s4.scousepy'):
s.load_stage_4(outputdir+filename+'/stage_4/s4.scousepy')
else:
s = scouse.stage_4(s, verbose=verb)
#==========================================================================#
# Stage 5
#==========================================================================#
if os.path.exists(outputdir+filename+'/stage_5/s5.scousepy'):
s.load_stage_5(outputdir+filename+'/stage_5/s5.scousepy')
else:
s = scouse.stage_5(s, blocksize = 6,
figsize = [18,10],
plot_residuals=True,
verbose=verb)
#==========================================================================#
# Stage 6
#==========================================================================#
if os.path.exists(outputdir+filename+'/stage_6/s6.scousepy'):
s.load_stage_6(outputdir+filename+'/stage_6/s6.scousepy')
else:
s = scouse.stage_6(s, plot_neighbours=True,
radius_pix = 2,
figsize = [18,10],
plot_residuals=True,
write_ascii=True,
verbose=verb)
return s
s = run_scousepy()
This format was largely introduced to prevent people from overwriting their hard work. In this way each stage can be run independently, without having to run the process from start to finish.
Tips and Tricks¶
One thing that I have found particularly useful in my own work is to break the
fitting process up into chunks. This can be really helpful if you have a lot of
spectra to fit. I have included a bitesized fitting process into scousepy
which can be run in stage 2 in the following way…
if os.path.exists(datadirectory+filename+'/stage_2/s2.scousepy'):
s.load_stage_2(datadirectory+filename+'/stage_2/s2.scousepy')
else:
s = scouse.stage_2(s, verbose=verb, write_ascii=True, bitesize=True, nspec=10)
s = scouse.stage_2(s, verbose=verb, write_ascii=True, bitesize=True, nspec=100)
Check out the Complete Example in the tutorial
section of the documentation to understand what is going on here with some more
context. However, in short, the first run I have used the keywords bitesize=True
and nspec=10. This will fit the first 10 spectra as normal. Note the
indentation on the second call to stage 2. After the first run with 10 spectra
each subsequent call to the code will load the s2.scousepy file and then
100 spectra will be fitted until the process is complete. Of course, you can
change this to whatever value you like.